The application of next-generation sequencing to unresolved familial disease
- Started
- 1st October 2012
- Ended
- 30th September 2015
- Research Team
- Jane Gibson, Reuben Pengelly
- Investigators
- Andrew Collins, Sarah Ennis
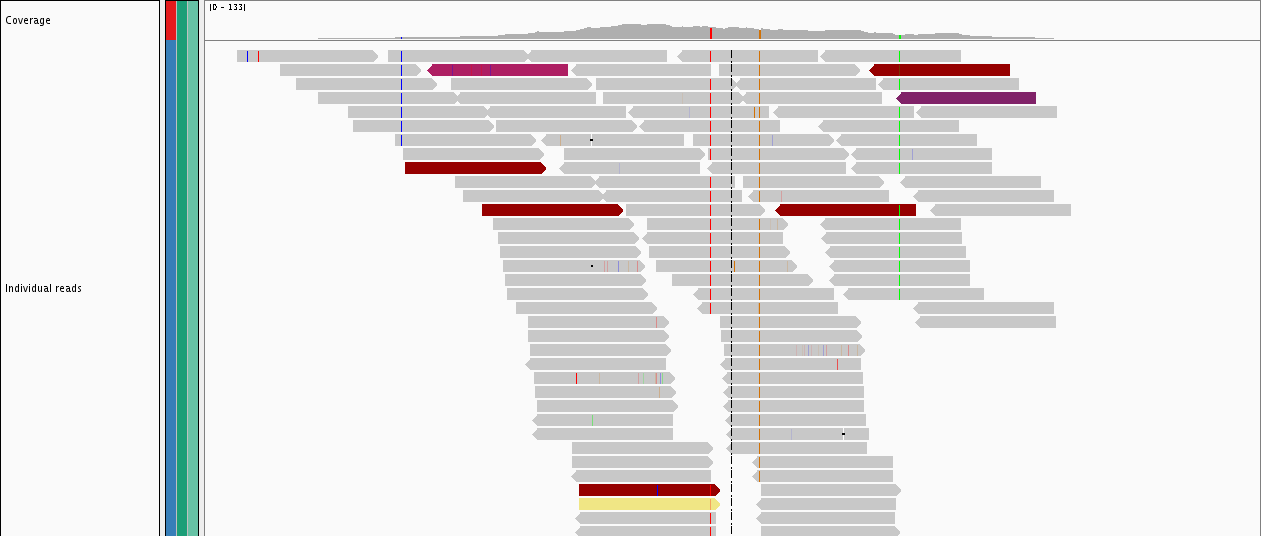
NGS short reads aligned to the human genome for one exon. Mutations are seen as coloured vertical lines on reads.
It is now technologically possible to sequence significant amounts of the genome in a cost-effective manner for use in clinical diagnostics and the discovery of novel genetic causes of disease. Next-generation sequencing generates millions of short-reads of the DNA, however, the in silico analysis of the resulting data is non-trivial, requiring advanced computing facilities such as Iridis to be undertaken effectively.
Currently, exome-sequencing, where the protein-coding regions of the genome (ca. 1% of the whole genome) are targeted for sequencing is one commonly used method due to the cost-effective nature. This 1% of the genome is estimated to contain 85% of disease-causing mutations, so this approach provides a high success rate. The unbiased approach to gathering of genetic data allows it to even be of use when the likely genetic candidates are unknown.
This project encompasses both the routine application of exome-sequencing, and method development for important issues such as the high level of quality control required for clinical application of the technologies.
Categories
Life sciences simulation: Bioinformatics, Biomedical, Epidemiology, NextGen Sequencing
Computational platforms: Iridis, Linux, Windows
Transdisciplinary tags: Quantitative Biology